

Alibaba Qwen3-Omni, Meituan LongCat, DeepSeek Upgrade, Nvidia’s $100B Investment & ByteDance Translation AI
Artificial Intelligence in 2025 is witnessing an unprecedented wave of upgrades and strategic investments. From Alibaba’s groundbreaking all-modal model, to Meituan’s reasoning-focused AI, DeepSeek’s open-source optimizations, Nvidia’s $100 billion bet on OpenAI, and ByteDance’s powerful translation model — the global AI industry is entering a new era of multi-modality, reasoning, and cross-lingual intelligence.
This article takes a deep dive into these major announcements and their implications for the future of AI.

The Global AI Race: Multi-Modal, Reasoning, and Translation
The AI competition in 2025 is crystallizing into three major tracks:
- All-modal intelligence – Unified models covering text, images, audio, and video.
- Reasoning and domain expertise – High-performance models for math, coding, and scientific applications.
- Cross-lingual communication – Reducing barriers through advanced translation and speech AI.
Let’s break down the five most important developments.
Alibaba Qwen3-Omni: The World’s First All-Modal AI Model
All-modal capabilities and real-time streaming
Alibaba has open-sourced Qwen3-Omni, the first model capable of handling text, images, audio, and video simultaneously. Unlike traditional models, it supports real-time streaming output, allowing responses to appear as the input unfolds.

Support for 119 languages
With 119 text languages and robust multilingual speech interaction, Qwen3-Omni enables seamless global communication.
Complementary tools: Qwen3-TTS & Qwen-Image-Edit-2509
- Qwen3-TTS: Offers 17 voice tones with high stability and natural similarity.
- Qwen-Image-Edit-2509: Significantly improves complex image editing tasks such as multi-object replacement and style transfer.
This positions Alibaba as an early leader in the all-modal AI race.
Meituan LongCat-Flash-Thinking: 560B Parameter Reasoning Model
MoE architecture with dynamic activation
Meituan’s LongCat-Flash-Thinking leverages a Mixture-of-Experts (MoE) architecture with 560 billion parameters in total. During inference, it activates only 18.6B–31.3B parameters (average ~27B), optimizing efficiency without sacrificing performance.
Performance close to GPT5-Thinking
The model excels in logical reasoning, mathematics, and programming, with benchmark results approaching GPT5-Thinking. This makes it highly valuable for finance, research, and complex software engineering.
DeepSeek-V3.1-Terminus: Open-Source Model Optimization
Fixes and improvements
DeepSeek-V3.1-Terminus addresses previous issues such as language inconsistencies and abnormal characters, making it more reliable in production.
Performance gains in programming and search
- Substantial improvements in coding tasks and search agents.
- Performance boost of 0.2%–36.5% in non-agent testing, with HLE (High-Level Reasoning) showing the most gains.
- Minor but consistent improvements in browsing, Q&A, and coding tasks.
This release underscores DeepSeek’s commitment to open-source AI ecosystems.
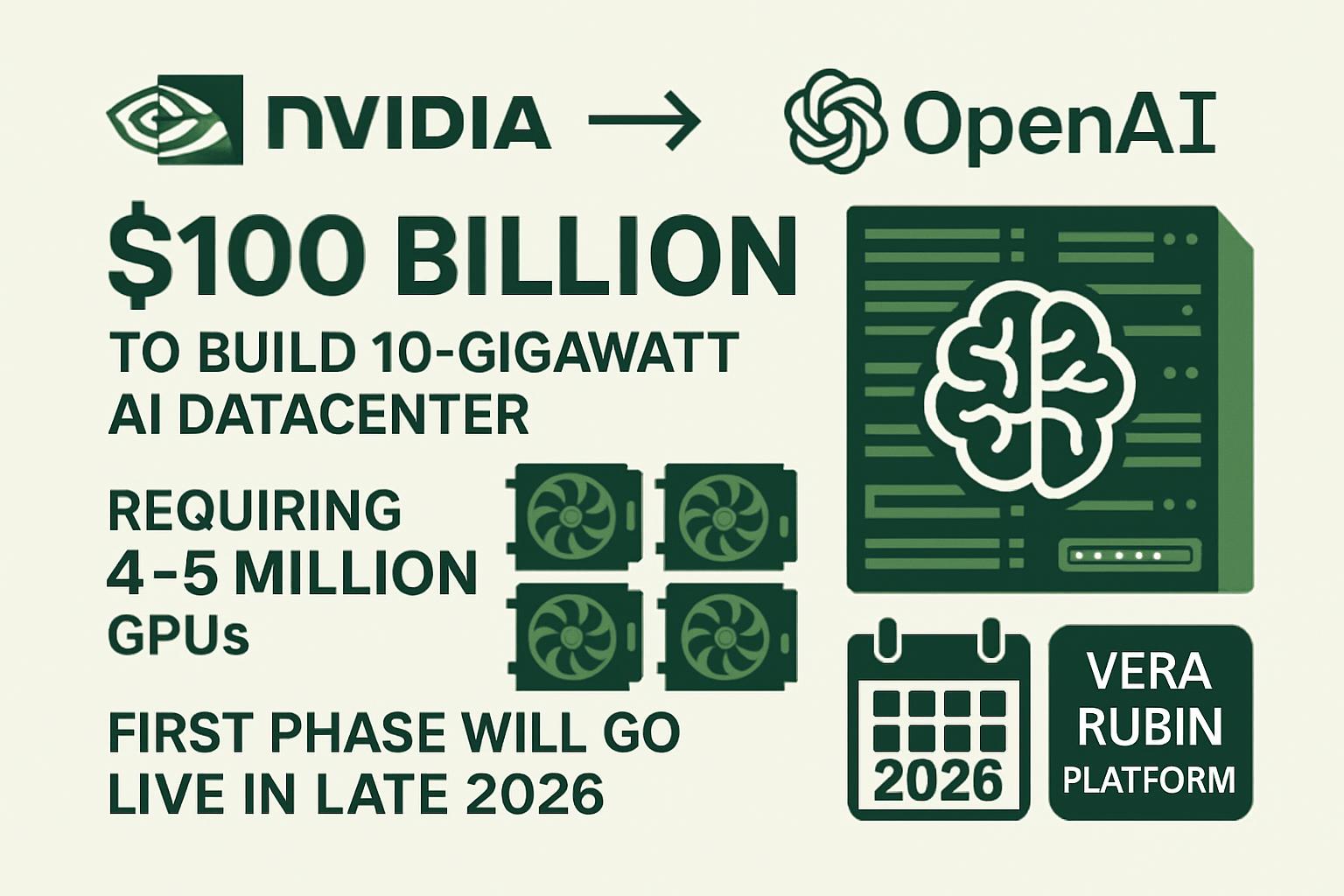
Nvidia’s $100B Investment in OpenAI: Scaling Compute Power
10GW AI datacenter with millions of GPUs
Nvidia is preparing a $100 billion investment in OpenAI to build a 10-gigawatt AI datacenter, requiring 4–5 million GPUs. The first phase will go live in late 2026, using the latest Vera Rubin platform.
Strategic partnerships
Recent moves include:
- $5 billion stake in Intel to co-develop new AI chips.
- $700 million investment in UK-based Nscale to strengthen its European presence.
Nvidia is solidifying its role as the world’s AI infrastructure backbone through capital + compute dominance.
ByteDance Doubao-Seed-Translation: Multilingual Translation Breakthrough
28 languages supported
ByteDance launched Doubao-Seed-Translation, supporting 28 languages including Chinese, English, Japanese, and Korean — ideal for cross-border collaboration.
Performance rivaling GPT-4o & Gemini-2.5-Pro
Benchmarks show its performance is on par with or surpasses GPT-4o and Gemini-2.5-Pro, especially in contextual understanding and natural fluency.
Highly competitive pricing
- Input: ¥1.20 per million characters
- Output: ¥3.60 per million characters
This aggressive pricing strategy offers a significant cost advantage over global competitors, making it attractive for e-commerce, international education, and global enterprises.
Global AI Market Trends and Commercial Outlook
- All-modal AI becomes the new standard — Alibaba has set the tone.
- Reasoning ability is the key differentiator — Meituan and DeepSeek are pushing boundaries.
- Capital drives infrastructure dominance — Nvidia is consolidating its supremacy.
- Cross-lingual communication explodes in demand — ByteDance may dominate translation for global businesses.
Conclusion: Entering the “All-Modal + Reasoning + Translation” Era
The trajectory of AI in 2025 is clear:
- All-modal intelligence for natural human-computer interaction.
- Reasoning excellence for research, finance, and technical domains.
- Multilingual fluency for global business integration.
At the same time, Nvidia’s $100B datacenter investment signals that compute power is the new oil of the AI age. Together, these forces mark the dawn of a new AI ecosystem — smarter, faster, and more globally connected.
FAQs
Q1: What makes Alibaba’s Qwen3-Omni special?
It’s the world’s first all-modal AI model that handles text, images, audio, and video with real-time streaming output.
Q2: How does Meituan’s LongCat compare to GPT models?
On reasoning, math, and coding benchmarks, it reaches performance close to GPT5-Thinking.
Q3: What’s new in DeepSeek-V3.1-Terminus?
It fixes language consistency issues and improves programming, search, and reasoning tasks.
Q4: Why is Nvidia investing $100 billion in OpenAI?
To build a 10GW datacenter with up to 5 million GPUs, reinforcing its global compute dominance.
Q5: How does ByteDance’s translation model stand out?
It supports 28 languages, costs significantly less than Western models, and rivals GPT-4o in performance.
Read More Industry Updates
Bringing you the latest news in the AI industry.






Leave a Reply